The Oxford-NINJAL Corpus of Old Japanese (abbreviated ONCOJ) is a long-term collaborative research project between the University of Oxford and the National Institute for Japanese Language and Linguistics, which is developing a lemmatized, parsed and comprehensively annotated digital corpus of all texts in Japanese from the Old Japanese period.
Old Japanese is the earliest attested stage of the Japanese language, largely the Japanese language of the Asuka and Nara periods of Japanese history (7th and 8th century AD). This is the formative literate period upon which the development of Japanese civilization is based, and these texts are of paramount importance for the study and understanding of the origins and development of the civilization of Japan, including language, writing, literature, religion, history, and culture.
The ONCOJ has been ongoing since 2011 (until 2017 under the name “The Oxford Corpus of Old Japanese (OCOJ)”). It was initially conceived of and designed as a resource for linguistic research, but it also includes features useful for work in history, literature, culture, etc. In its present version, the ONCOJ contains the full corpus of Old Japanese poetic texts, including the Man'yōshū.
The ONCOJ is supported and recognized by the British Academy as an Academy Research Project. At NINJAL it forms part of the large Extending the Diachronic Corpus through an Open Co-construction Environment project. The present website is hosted on the NINJAL server.
This website gives access to the texts of the ONCOJ and the associated dictionary. The data presented here comprise a corpus of around 90,000 words of poetic text (at the latest count 99,828 simple lexical items (either in isolation or in compounds) combined with 15,635 bound morphemes). The texts are fully lemmatized and have annotation for mode of writing (phonographic or logographic), morphology and syntactic parsing.
The Dictionary, Texts, and the Search interface give direct access to the texts, the dictionary, and a suite of powerful on-line search tools that enable search using virtually any aspect of the annotation, plus interfaces for downloading search results in the form of annotated data.
The texts are accessible here in a simple form, with original script and phonemic transcription side by side, and with links to views of text in the form of constituency trees (among other options) in the Search interface. The texts may also be accessed directly through the Search interface which provides a variety of search tools and download facilities. The Search interface also includes a Dictionary of the words appearing in the corpus.
Where available, links to corresponding texts in the Nara Period Series of the NINJAL Corpus of Historical Japanese are provided in the constituency tree view in the Search interface.
The source data of the corpus is updated in real time as editors make changes to reflect improvements in analysis. The website will be updated regularly to add more user functionality. Expansion and improvements are planned and ongoing in several areas.
As with any annotated text corpus, there are mistakes in the ONCOJ. The corpus is ongoing work and is under continuous improvement and correction. Mistakes will be corrected as we become aware of them and as time allows. We will be grateful to be made aware of mistakes and will endeavour to eliminate mistakes with the help of users (contact). Mistakes may be found in all four main areas of annotation: lemmatization, mode of writing, morphology, and syntactic parsing, as well as in original text and transcription, and in glosses in the dictionary.
The ONCOJ draws its data from critical editions of OJ texts, with texts transcribed phonemically and edited to parallel the content from corresponding items in well-known critical editions and their interpretations. Where editions differ we have in most cases followed the authority of the Nihon koten bungaku taikei (Iwanami Shoten). The OJ poetic texts are the following (showing here also the standard abbreviations for text loci, e.g., MYS for texts from the Man'yōshū).
The original texts were written in Chinese characters, used both phonographically and logographically. The corpus presents the texts in a phonemic transcription, richly annotated with lexical, morphological and syntactic information and structure, accompanied by the original script.
The text of the annotated corpus is in the form of a phonemic transcription from the original script of the source texts, in Frellesvig-Whitman notation. The following table summarizes the differences in the way the distinction between kō-rui (甲類) and otsu-rui (乙類) syllables are represented in various notation systems (including Ohno Susumu's system as used for example in the Iwanami kogo jiten and the Yale system of Samuel E. Martin’s The Japanese language through time).
| Syllable type | Index notation | Ohno | Modified Mathias- Miller | Yale | Frellesvig & Whitman |
| Kō-rui | Ci1 | Ci | Cî | Cyi | Ci |
|---|---|---|---|---|---|
| Otsu-rui | Ci2 | Cï | Cï | Ciy | Cwi |
| Neutral | Ci | Ci | Ci | Ci | Ci |
| Kō-rui | Ce1 | Ce | Cê | Cye | Cye |
| Otsu-rui | Ce2 | Cë | Cë | Cey | Ce |
| Neutral | Ce | Ce | Ce | Ce | Ce |
| Kō-rui | Co1 | Co | Cô | Cwo | Cwo |
| Otsu-rui | Co2 | Cö | Cö | Co | Co |
| Neutral | Co | Co | Co | Co | Co |
The following table presents some examples of how these different systems write words of Old Japanese, with the 'NJ' column showing the shape of the word in Modern Japanese.
| Gloss | NJ | Frellesvig & Whitman | Index notation | Yale | Modified Mathias-Miller | Ohno |
| 'sun' | hi | pi | pi1 | pyi | pî | pi |
|---|---|---|---|---|---|---|
| 'fire' | hi | pwi | pi2 | piy | pï | pï |
| 'blood' | chi | ti | ti | ti | ti | ti |
| 'woman' | me | mye | me1 | mye | mê | me |
| 'eye' | me | me | me2 | mey | më | më |
| 'hand' | te | te | te | te | te | te |
| 'child' | ko | kwo | ko1 | kwo | kô | ko |
| 'this' | ko | ko | ko2 | ko | kö | kö |
| 'ear (of rice)' | ho | po | po | po | po | po |
Old Japanese writing practice employed two basic modes of writing: phonographic writing, in which Chinese characters represent OJ syllables, and logographic writing, in which Chinese characters represent OJ words or morphemes. In transcription, phonographically written text is shown in italics and logographically written text is shown in plain text; text portions which have no direct representation in writing (usually functional elements of some kind) are shown in underlined plain text.
三芳野之
miyosinwo no
青根我峯之
awone ga take no
蘿席
kokemusiro
誰将織
tare ka orikyemu
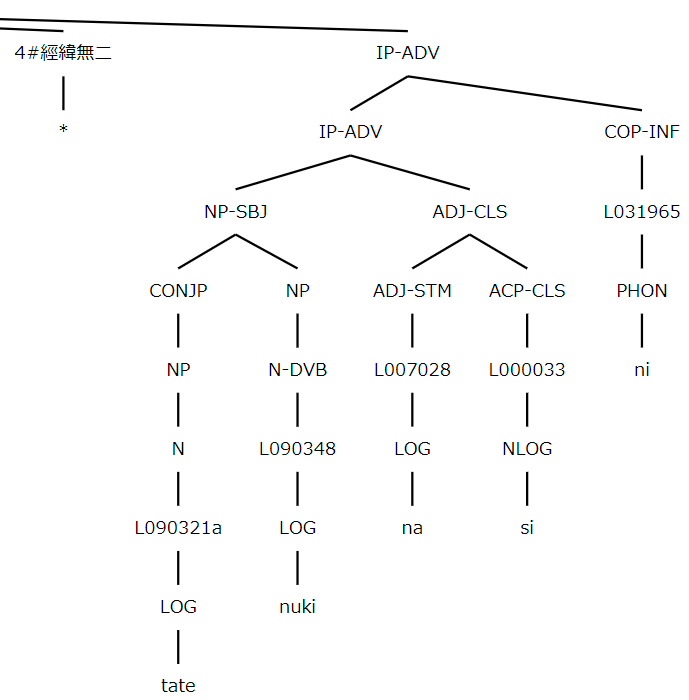
經緯無二
tatenuki nasi ni
'The moss matting / of Aonegatake / in Miyoshino /
-- who must have woven it, / with neither warp nor weft?'
(MYS.7.1120)
[Aonegamine, Ōmine range, Nara, Japan]
Case and other particles (like genitive ga or focus so), modal extensions (like presumptive rasi) and the copula are presented as individual words and not as enclitics.
Words in a text form units (constituents) which combine with other words to form larger constituents (phrases and clauses), and ultimately whole sentences. In the Search interface, the organization of units is presented in the form of tree structures.
In the trees, text is segmented into terminal nodes (strings). Strings are separated into segments primarily by boundaries between morphemes, but within morphemes strings may also be segmented according to changes in the mode of writing. In the ONCOJ data, the mode of writing for every segment is indicated using nodes labeled, the principal ones being, respectively, PHON (phonographic), LOG (logographic), NLOG (no direct representation). There is an additional category for place names, PLOG, and another for illegible items, ILL. Thus a word may be composed of one or more morphemes, but a full morpheme may be composed of several segments, depending on how it is written in the original text.
Immediately above the segment(s) for each full morpheme is a lemma ID. For example, L000503 appears immediately above (or “directly dominates”) the string ga. Each lemma ID corresponds to a morpheme with a specific part-of-speech. Directly dominating the lemma ID node is the part-of-speech node, which has a label specifying the part-of-speech for that morpheme (e.g., PFX = prefix; N = noun; P = particle; VB = verb; ADJ = adjective, etc.). Thus, P-CASE-GEN is the label for the genitive case particle ga with lemma ID L000503. Part-of-speech nodes can either label simplex words or they can label morphemes that combine into complex words, which in turn receive their own part of speech nodes.
Directly dominating nodes at the word level are phrasal nodes (e.g., NP = noun phrase; PP = particle phrase; IP = inflectional phrase; CP = complementizer phrase, etc.). Labeled nodes frequently appear with extensions that specify functional information (e.g., NP-OB1 = direct object noun phrase; PP-SBJ = subject particle phrase; IP-ADV = adverbial inflectional phrase, etc.). In the trees, the structure of an inflectional phrase (clause) is flat, with no verb phrases or functional projections. Hence, local argument dependencies and modifier dependencies are defined by sisterhood to the target head. The basic format is similar to that used in the Penn Parsed Corpora of Historical English. For an overview of these principles applied to NJ, see the annotation manual in the Keyaki Treebank (Butler, et al. 2017).
A full list of the labels used in the corpus is available here
Note that line breaks are numbered from 0 ~ n -1, and the original text for the n-th line of a poem is included under the line break numbered n -1. In the figure above (the fifth line of MYS.7.1120), the original text for line 5 appears under line break number 4#.
The corpus is currently associated with a powerful on-line search interface, introduced here, which allows for results of specific searches to be be downloaded. The interface allows searches to be defined using regular expressions, node labels, and structural conditions.
The available on-line interface is a powerful and flexible tool sufficient for many research purposes, but note that the data on which it operates is updated in real time. For extended research projects it is often advisable to download a release version for use off-line. This not only provides the advanced researcher a stable set of data, but also allows for manipulation of the data to reflect analyses that are not included in the present online corpus but are necessary for a given research project. The full corpus is available for download for use with off-line search tools like Tregex (Levy and Andrew, 2006) and CorpusSearch2 (Randall, 2009).
The Oxford-NINJAL Corpus of Old Japanese should be cited and referenced inline as
Frellesvig, Horn et al. (2026)
and in the list of references as
Frellesvig, Bjarke, Stephen Wright Horn et al. (eds.) 2026. Oxford-NINJAL Corpus of Old Japanese. Available at: http://oncoj.ninjal.ac.jp/ (accessed February 2026)
with details depending on the format of referencing you use and with appropriate modification of the dates depending on the date of access.
This work is licensed under a Creative Commons Attribution 4.0 International License.
