オックスフォード・NINJAL上代語コーパス(ONCOJ) はオックスフォード大学と国立国語研究所 (NINJAL) との長期の共同研究プロジェクトで、上代日本語のテキストを対象に包括的な形態・統語解析アノテーションを付与したコーパスを開発している。 ONCOJ は アカデミー研究プロジェクト (Academy Research Project) として英国アカデミーから支援を受けている。 NINJAL においては 通時コーパスの構築と日本語史研究の新展開という大規模の共同研究プロジェクトの一貫として進められていた。 本ウエブサイトは NINJAL のサーバーで保管されている。
上代語とは文献が残っている日本語の実例として最古のものであり、飛鳥時代から奈良時代(7〜8世紀)にわたって使用されていた。 その当時の文化は現代日本文化の拠り所であり、上代日本語のテキストは言語、文学、歴史の発展を理解するには重要な資料になる。
ONCOJ は2011年から2017年まで "The Oxford Corpus of Old Japanese (OCOJ)"という名のもとで構築が進められた。 当初は言語学の研究ツールとして設計されたが、歴史、文学、文化などに研究に役立つ要素をも取り入れている。 現在の形では、 ONCOJ は萬葉集を始め、上代日本語の歌謡テキストのすべてを収録している。
2021年3月のバージョン (Version 2021.3) に代わり、現在のこのウェブサイトは ONCOJ の5度目の公開 (Version 2021.10) にあたる。 改定したデータとともに様々な検索機能を含み、アノテーションのあらゆる要素にもとづいて検索ができ、アノテーションごとの検索結果のみならず、データベースの元となる情報のすべてをダウンロードするためのインターフェースも付いている。 現在公開しているのは2021年10月14日時点のデータで、凡そ9万語の歌謡のテキストが収録されている。 99,828個の語彙的内容の形態素が、単語または複合語の形で 15,635 個の束縛形態素と組み合わさって、このコーパスを構成している。 データは見出し語同定、品詞同定と活用同定が処理済みであり、表記法が表音的か表語的かも分析され、これらに加えて文法の句構造や構成素の文法役割の情報も含まれている。
OJ テキストのページから、各テキストの原文とローマ字の読み下しが並列した形でコーパス全文にアクセスできる。 行ごとにそのテキストの直接構成素分析の樹形図へのリンクが付いている。 この分析表示は検索インターフェースの環境内のページであり、そこから様々な検索ツールにアクセスできる。 メニューからも検索インターフェース にアクセスできるが、一旦この環境に入ると、検索方法、検索結果の表示、データのダウンロードなどのオプションが色々ある。 その一つとして上代日本語の和英 辞書 があり、見出し語の ID 番号、品詞、英訳などが見られる。
ONCOJ のテキストとNINJAL の日本語歴史コーパスの奈良時代編 のテキストが対応している場合には、ONCOJ の分析表示のページにそのリンクが付いている。
メニューからダウンロード のページに行きデータ形式を選択すると、コーパスのデータをまるごとダウンロードできる。
コーパスというのは、アノテーションが完璧なものはおそらく存在しないので、現在公開中の ONCOJ にも不備なところがあることはいうまでもないであろう。 分析がまだ至っていないところ、分析自体を改良する余地が残っているところについては、作業が進行中であるので、これからも出来る限り直していく方針である。 これにあたってコーパスの使用者からご指摘をいただけるとありがたい(連絡先)。 原文やその読み下しだけではなく、見出し語の同定、表記法の分類化、形態素解析や統語分析というアノテーションのレベルにも、辞書の英訳にも、問題が残っている。 現在の公開では、特にナ行とハ行の語の分析において手作業の見出し語の同定がまだ終わっていないので、ご注意ください。
データの訂正・改良・形式や使用者のための機能を増加し、このウェブサイトを定期的に更新する方針である:アップデート 。 具体的な改良・拡大については 計画・抱負 をご覧ください。
ONCOJ 上代語が含まれる作品の校訂版をデータの拠り所とし、その読み下しや意味解釈を参考にローマ字化、形態素解析、統語的構造分析などを行う。 校異のある場合は主に岩波書店の『日本古典文学大系』に従う。 以下の表で上代日本語の歌謡のデータの出典となる作品の題名とそれに対応するコーパスの省略:『萬葉集』 (MYS) など。
本コーパスの原文は漢字で書かれ、表語的と表音的両方の表記法が使われた。 そういったテキストの読み下しをローマ字化し、アノテーションとして形態論・語彙論・統語論の3つのレベルの情報を付与する。
その読み下しをローマ字化し、アノテーションとして形態論・語彙論・統語論の3つのレベルの情報を付与し、原文と関係づける。 ローマ字化原文の読み下しをローマ字化した形で本コーパスのテキストを表示するには Frellesvig-Whitman 式の綴り方を使用している。 以下の表で上代特殊仮名遣いの甲類と乙類との区別の表し方(大野晋による『岩波古語辞典』の綴りや Samuel E. Martin の The Japanese language through time で使用される Yale 式綴り方など)を対比する。
| Syllable type | Index notation | Ohno | Modified Mathias- Miller | Yale | Frellesvig & Whitman |
| Kō-rui | Ci1 | Ci | Cî | Cyi | Ci |
|---|---|---|---|---|---|
| Otsu-rui | Ci2 | Cï | Cï | Ciy | Cwi |
| Neutral | Ci | Ci | Ci | Ci | Ci |
| Kō-rui | Ce1 | Ce | Cê | Cye | Cye |
| Otsu-rui | Ce2 | Cë | Cë | Cey | Ce |
| Neutral | Ce | Ce | Ce | Ce | Ce |
| Kō-rui | Co1 | Co | Cô | Cwo | Cwo |
| Otsu-rui | Co2 | Cö | Cö | Co | Co |
| Neutral | Co | Co | Co | Co | Co |
次の表ではいくつかの上代日本語の語に対するそれぞれの綴り方を対比する。 参考のために、各語に対応する現代日本語も示す。
| Gloss | NJ | Frellesvig & Whitman | Index notation | Yale | Modified Mathias-Miller | Ohno |
| 'sun' | hi | pi | pi1 | pyi | pî | pi |
|---|---|---|---|---|---|---|
| 'fire' | hi | pwi | pi2 | piy | pï | pï |
| 'blood' | chi | ti | ti | ti | ti | ti |
| 'woman' | me | mye | me1 | mye | mê | me |
| 'eye' | me | me | me2 | mey | më | më |
| 'hand' | te | te | te | te | te | te |
| 'child' | ko | kwo | ko1 | kwo | kô | ko |
| 'this' | ko | ko | ko2 | ko | kö | kö |
| 'ear (of rice)' | ho | po | po | po | po | po |
上代日本語の表記法は2種類に大別できる:漢字の音を借りて上代語の音節を表す表音的な表記法と、漢字でもって上代語の語や形態素を表す表語的な表記法。 このコーパスの OJ テキスト のページにおいては表音的な表記法で書かれたテキストは斜体 (italics) で表示され、表語的な表記法で書かれたテキストはプレーンのローマ字 (plain) で表示される。 文字で表されていないテキスト(添字ー機能語が多い)は下線部 (underlined) となっている。
三芳野之
miyosinwo no
青根我峯之
awone ga take no
蘿席
kokemusiro
誰将織
tare ka orikyemu
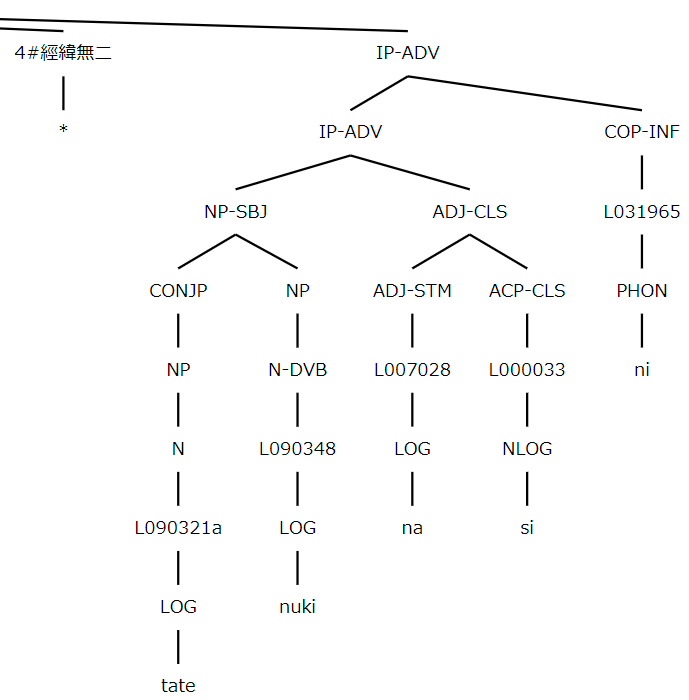
經緯無二
tatenuki nasi ni
'The moss matting / of Aonegatake / in Miyoshino /
-- who must have woven it, / with neither warp nor weft?'
(MYS.7.1120)
[Aonegamine, Ōmine range, Nara, Japan]
ONCOJ の形態素解析は A history of the Japanese language (Bjarke Frellesvig, Cambridge University Press, 2010) の分析を用いる。 伝統的な国語学とは相違点がいくつかある。 屈折語に関しては、伝統的な国語学の「活用形(未然形、連用形、已然形など)+接続助詞(「ば、ど、な、て」など)」と分析するところを、ONCOJ では各々の組み合わせを一つの屈折した形式として扱う。 例えば「開くれど」を「開く」の已然形+逆説の接続助詞「ど」 ではなく、その全体を「開く」の concessive の屈折形と分析する。
もうひとつの特徴として、助詞(所有格の「が」、取り立て助詞(「は」など)モダリティーの助動詞(推定の「らし」など)、コピュラ(断定助動詞)は接辞ではなく、単語として扱われている。
テキストの中では語は構成素という単位を成し、他の単語と組み合わさると、より大きな構成素(句や節)を作り、最終的には文を形成する。 検索インターフェースでは、こういった組織化した単位の連なりは樹形図(ツリー構造)の形で表示される。
ツリーではテキストが終末ノード(文字列)に分けられる。 多くの場合、文字列と文字列との境目は形態素の境界線にあたるが、一つの形態素の中でに2つ以上の表記法が用いられると、さらに細かく分けられる。 ONCOJ においてすべての文字列がその表記法を指定するラベル(ノード)の真下にある:PHON (表音的表記), LOG (表語的表記), NLOG (添字)。 このように、一つの語は二つ以上の形態素によって形成されたりするが、原文の表記法によって、一つの形態素が2つ以上の文字列から形成されたりもする。
表記法を表すノードの真上には単語の意味を指定する語彙素ID語番号のノードが置かれる(例えば、#L000503 は主格の助詞 ga の語彙素ID語番号で、ga の表記ノードとの品詞ラベル P-CASE-GEN の間にある)。
形態素の品詞ノード(例えば、PFX = prefix [接頭辞]、 N = noun [名詞]、 P = particle [助詞]、 VB = verb [動詞]、 ADJ = adjective [形容詞] など)は問題となっている形態素の語彙素ID語番号ノードの真上に置かれ、それらを直接支配する。 品詞ノードは自由形態素または束縛形態素を支配し、これらが組み合わさって合成語を形成する場合、その全体の真上にさらなる品詞ノードが置かれる。
語を直接支配するノードは句ノード[例えば NP = noun phrase [名詞句]、 PP = particle phrase [助詞句]、 IP = inflectional phrase [節]、 CP = complementizer phrase [補文]など)。 文法的機能を示すためにノードのラベルに拡張が付く場合がある(例えば、 NP-OB1 = direct object noun phrase [目的語の名詞句]、 PP-SBJ = subject particle phrase [主語の助詞句]、 IP-ADV = adverbial inflectional phrase [副詞節]など)。 ツリーに於いては節の構造は平らであり、「動詞句」や「機能の投射」などを設けないので、局所依存や副詞依存関係は主要部との姉妹関係にあたる。 この捉え方は Penn Parsed Corpora of Historical English に習ったものであり、現代日本語を対象にした実例については Keyaki Treebank (Butler, et al. 2017) を参照してください。
歌の句と句との境界を示す「改行」 (line break [lb]) には 0 ~ n -1 の番号が振ってあり、歌の第 n 行に対応する元の漢字テキストは第 n -1 の lb の下に置かれている。 したがって、以上の図は MYS.7.1120 の第5行をツリーで示しているが、その漢字表記は 4# の lb にある。
本コーパスのオンラインの検索インナーフェースでは、正規表現や Tregex という検索シンタックスを使って、文字列検索や複数の構成素の間の構造上の関係に基づいたツリー検索が可能。 検索結果をダウンロードする機能もある。 この意味では検索インタフェースは色々の研究に役立つ強力なツールであるといえよう。 しかし本コーパスを活かせるには TGrep (Pito 1994)、TGrep2 (Rohde 2005)、Tregex (Levy and Andrew-2006)、CorpusSearch2 (Randall, Taylor and Kroch)、TSurgeon (Levy) などのツールが最適であり、そのためにデータをまるごと ダウンロード し、オフラインでの使用を勧める。
この作品はクリエイティブ・コモンズ・ライセンスの下でライセンスされている: Creative Commons Attribution 4.0 International License.

文中で『オックスフォード・NINJAL 上代語コーパス』を引用する際は、下記の情報に基づいて出典を明記してください。
Frellesvig, Horn et al. (2025)
参考文献の項目は下記の情報に基づいて明記してください。
Frellesvig, Bjarke, Stephen Wright Horn et al. (eds.) 2025. Oxford-NINJAL Corpus of Old Japanese. Available at: "https://oncoj.ninjal.ac.jp/ (accessed 31 March 2025)
形式やアクセス年月日は適宜書き換えてください。